3 min read

Juan Andrade
Designing for growth
How do you design a great product, when you don’t have access to lots of customers (yet)?
For Founders

Rebank are huge fans of Superhuman, especially Rahul’s product/market fit engine, but we encountered a problem at the start of 2020… how do you design a great product, when you don’t have access to lots of customers (yet)?
Chicken, meet egg.

For those that don't know how the product/market fit survey works:
You first need around 200 users before you can optimise towards 40% of your audience responding ‘Very dissatisfied’ to the survey question: ‘How would you feel if you could no longer use our product?’ For obvious reasons it’s not possible to conduct product/market fit surveys with non-customers:

Talking to non-users
In January last year, we were working in the rebank office (enjoying the proximity to our teammates) and started to ponder this problem.
It was trivial to talk about the value of our existing research: discovery calls, journey mapping, user testing new features, or high-touch onboarding. But in the back of our minds, we were frustrated that we didn’t have something that would work towards product/market fit.
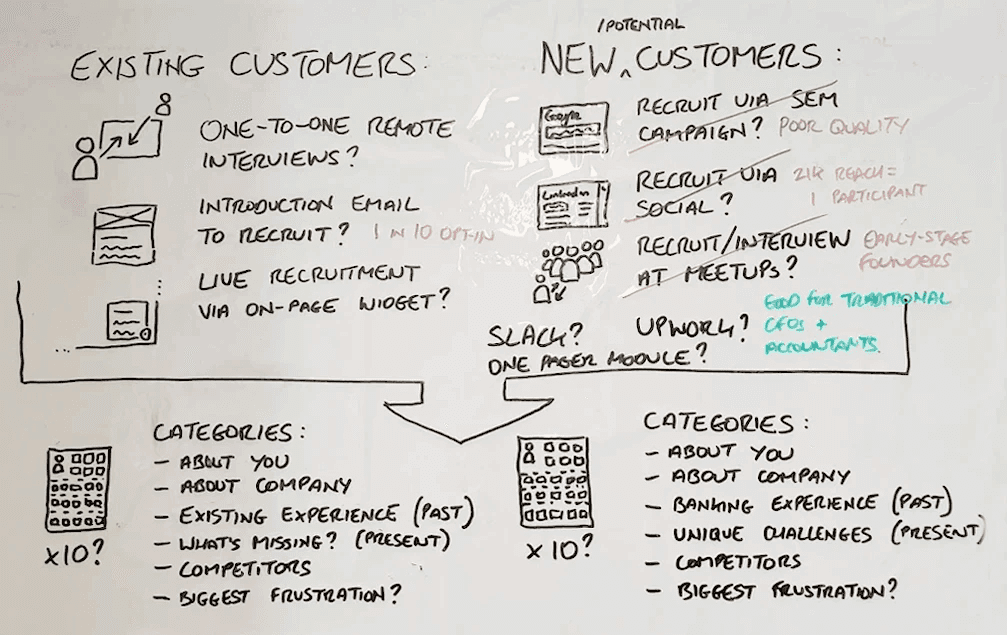
We decided to rethink product research from the ground up… we wanted a way of working towards product/market fit using the richest dataset that was available to us: millions of non-customers.
We knew we couldn’t ask our tight-knit community of customers: “How would you feel if you couldn’t use our product anymore?” as they were already part of our movement, they’d say: “We’d be gutted, we want to see you succeed.”
It’s the potential downside of social norms, where we're primed as humans to be nicer to one another (usually).
To find market norms instead, we approached non-customers who were more than happy to give us their honest feedback (especially if we asked for it). We experimented with success metrics, before deciding on cold, hard conversion from research sessions: how many non-customers wanted to use rebank after using a prototype? Drum-roll… in January 2020… around 8%
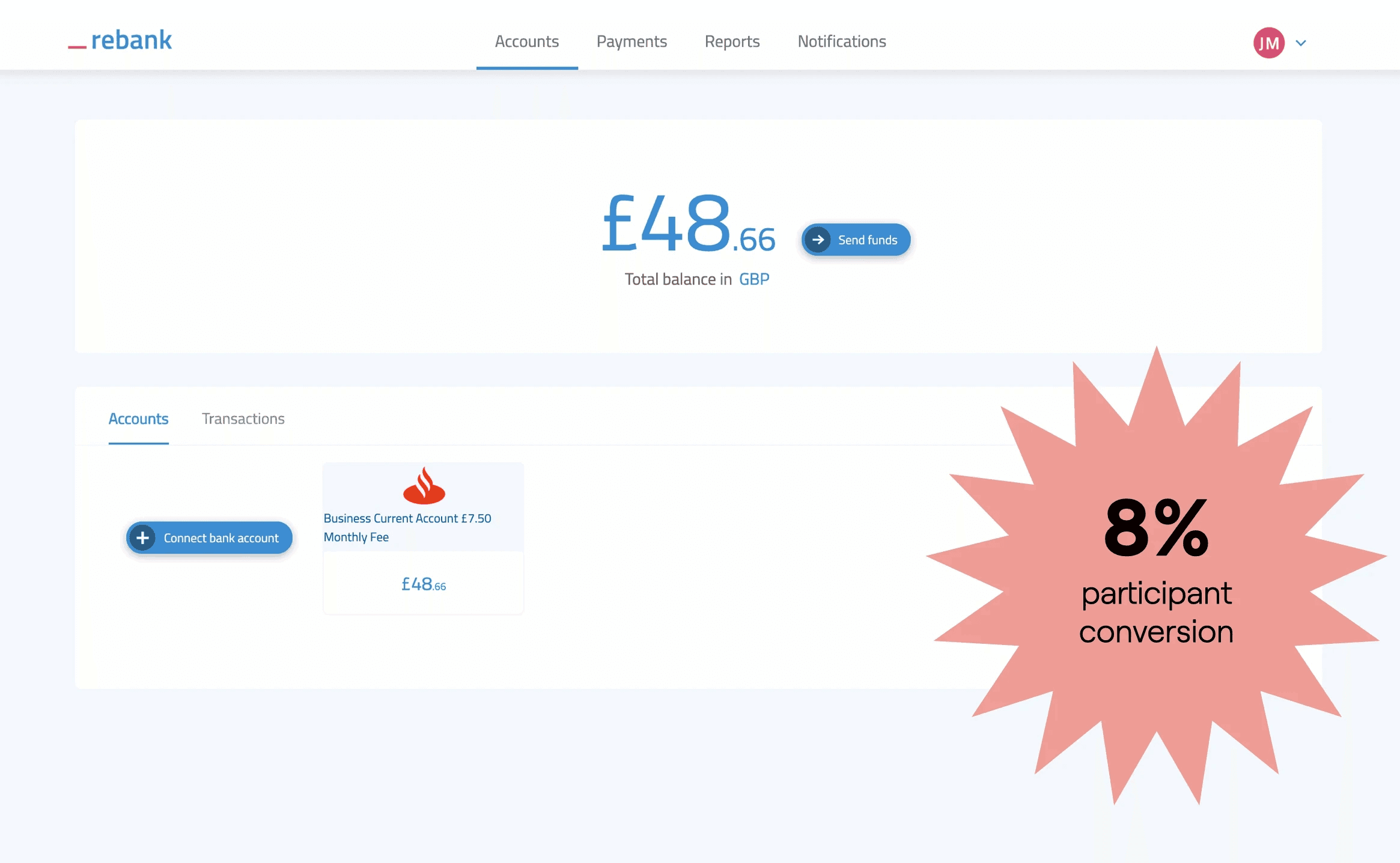
But now we could discover why.
The beauty of a framework is the ability to optimise it… much like Superhuman’s engine, we could now run the following analysis:
Which segments see the highest conversion from research sessions?
When looking at conversions as a whole, what other (non-majority) positive themes can be inferred?
What does our highest converting segment love about our product?
What other problems does our highest converting segment wish we solved for them (and crucially how painful is that problem/how motivated are they to solve it)?
Using the simple questions above enabled us to filter early-stage potential customers rapidly (a challenge for another time). We could also refine our understanding of our ideal customer using non-majority themes/lenses.
We set a target of converting 50% of research participants into customers.
Breaking down the insights
Research sessions were producing lots of rich data so after some refinement, we decided to break qualitative research sessions down into verbatim quotes or one-liner observations in an atomic research table.
We tagged our findings as ‘existing product value’ (features to double down on) or ‘problems to solve’ (things to work on next). It became straightforward to explore the data because every atom of research was associated with a real person and that person was associated with a real company in our CRM.

Some of the features we decided to double down on included: international payments, managing foreign currency and avoiding bank logins entirely.
Some of the new problems we solved included: giving your co-founder access to your banks (in 3 clicks), paying multiple invoices at once, optimising monthly spend using custom categories and an instant runway calculation.
By focusing on non-customers that converted, doubling down on the most-loved features and solving the most painful problems, we managed to achieve our aim and increased research conversion to 66%, beating our 50% target.
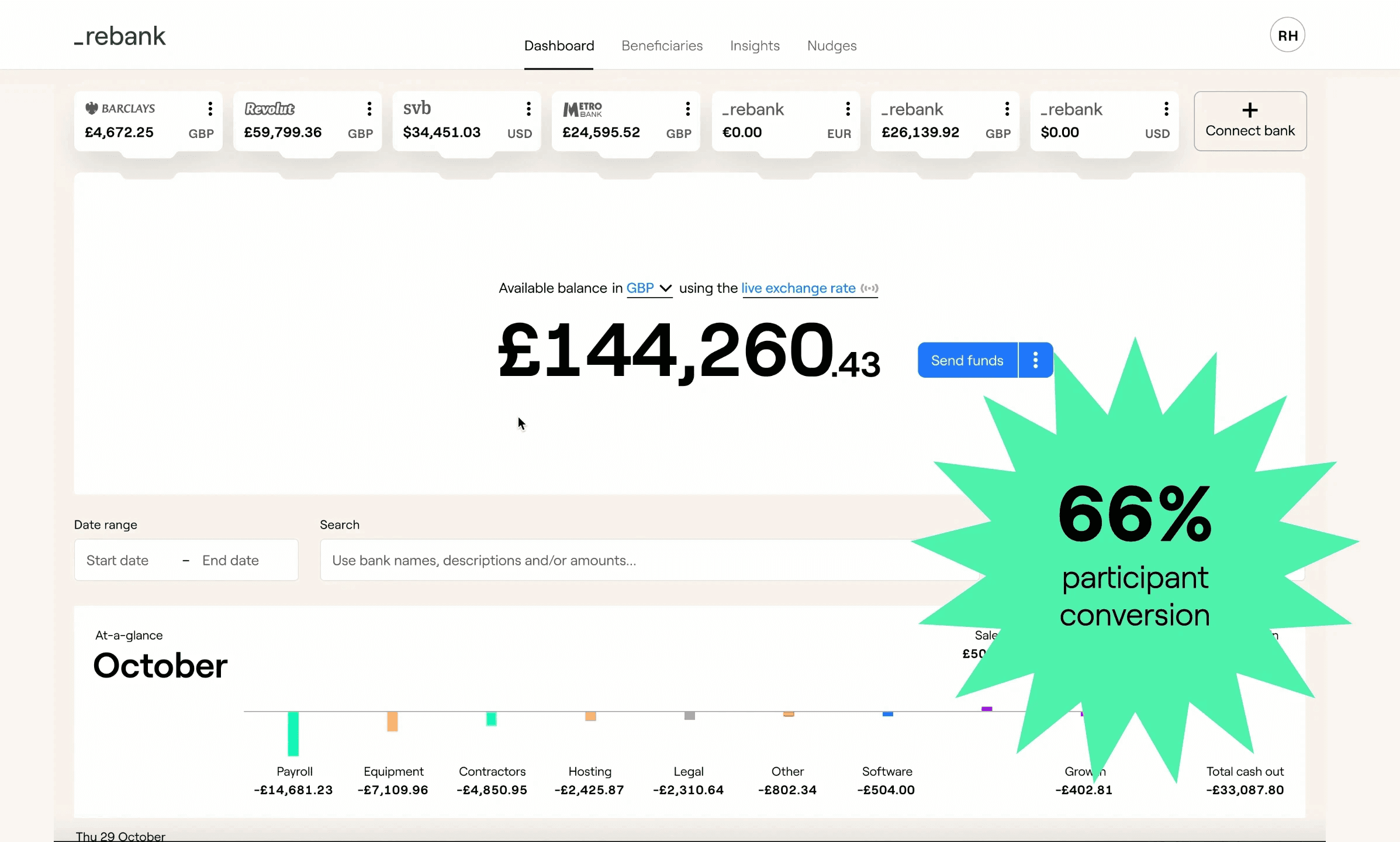
The research channel conversion was in addition to the customers we were acquiring through more traditional channels, such as the rebank website.
Know someone who needs to read this?
Juan Andrade
Founder, Caribou
Further reading
Our team has worked in the industry for years, and we’re here to share what we have learnt with you.

5 min read
Juan Andrade
14 May 2025
Building a product using Shape Up methodology.
Shape Up was created by the founders of Basecamp and is broadly based around three phases of work that happen within a “cycle” — typically 6 weeks in duration
For Founders

3 min read
Juan Andrade
14 May 2025
Traction, meet user research!
We didn’t want to ask existing customers to commit to multiple research sessions. This is how we continued to gain momentum by talking to non-customers
For Founders